


L’optimisation des liens internes est importante si vous souhaitez que les pages de votre site aient suffisamment d’autorité pour être classées pour leurs mots-clés cibles. Par liens internes, nous entendons les pages de votre site Web qui reçoivent des liens d’autres pages.
C’est important car c’est la base sur laquelle Google et d’autres recherches calculent l’importance de la page par rapport aux autres pages de votre site Web.
Il affecte également la probabilité qu’un utilisateur découvre du contenu sur votre site. La découverte de contenu est la base de l’algorithme PageRank de Google.
Aujourd’hui, nous explorons une approche axée sur les données pour améliorer les liens internes d’un site Web en vue d’un référencement technique plus efficace. Il s’agit de s’assurer que la distribution de l’autorité du domaine interne est optimisée en fonction de la structure du site.
Améliorer les structures de liens internes avec la science des données
Notre approche basée sur les données se concentre sur un seul aspect de l’optimisation de l’architecture des liens internes, qui consiste à modéliser la distribution des liens internes en fonction de la profondeur du site, puis à cibler les pages qui manquent de liens pour leur profondeur particulière.
Nous commençons par importer les bibliothèques et les données, en nettoyant les noms des colonnes avant de les prévisualiser :
import pandas as pd
import numpy as np
site_name="ON24"
site_filename="on24"
website="www.on24.com"
# import Crawl Data
crawl_data = pd.read_csv('data/'+ site_filename + '_crawl.csv')
crawl_data.columns = crawl_data.columns.str.replace(' ','_')
crawl_data.columns = crawl_data.columns.str.replace('.','')
crawl_data.columns = crawl_data.columns.str.replace('(','')
crawl_data.columns = crawl_data.columns.str.replace(')','')
crawl_data.columns = map(str.lower, crawl_data.columns)
print(crawl_data.shape)
print(crawl_data.dtypes)
Crawl_data
(8611, 104)
url object
base_url object
crawl_depth object
crawl_status object
host object
...
redirect_type object
redirect_url object
redirect_url_status object
redirect_url_status_code object
unnamed:_103 float64
Length: 104, dtype: object
 Andreas Voniatis, novembre 2021
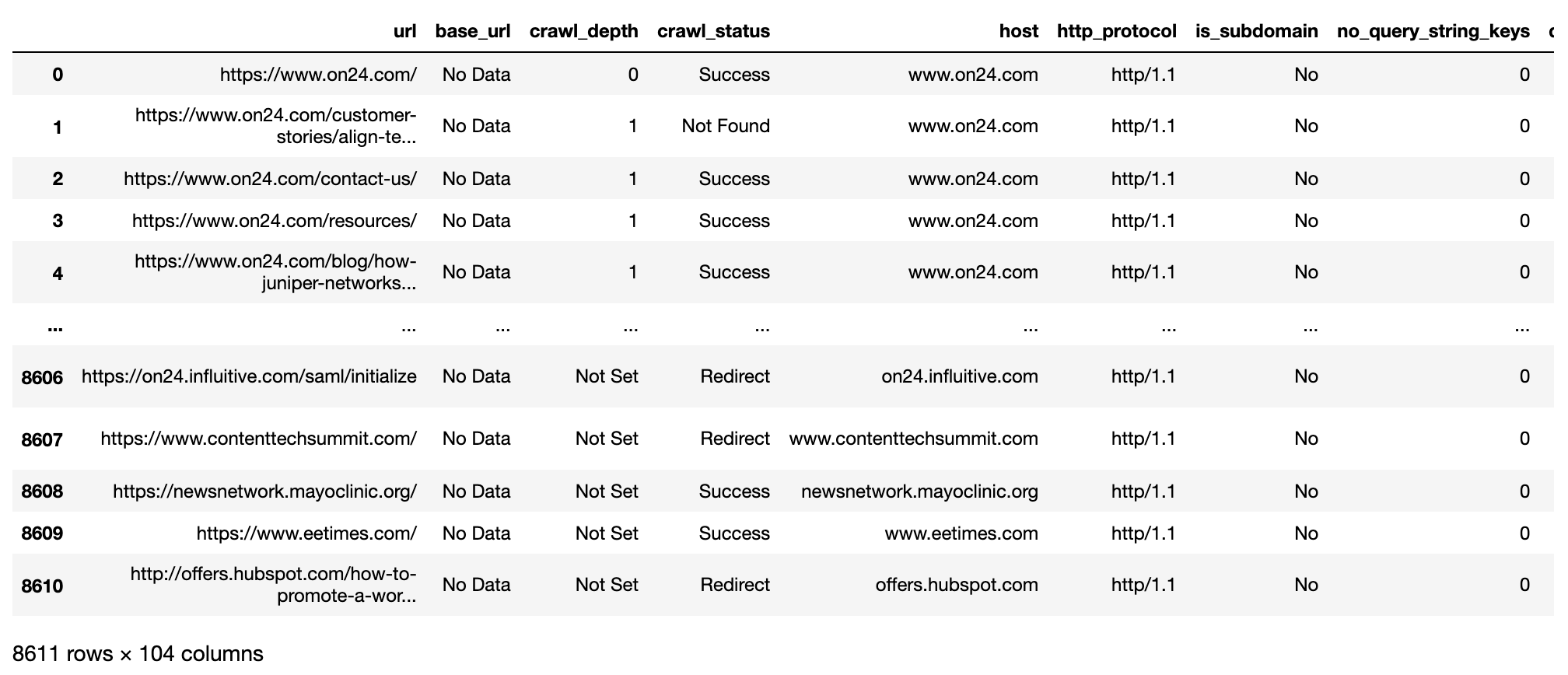
Andreas Voniatis, novembre 2021L’image ci-dessus montre un aperçu des données importées à partir de l’application Sitebulb desktop crawler. Il y a plus de 8 000 lignes et toutes ne seront pas exclusives au domaine, car elles comprendront également les URL des ressources et les URL des liens sortants externes.
Nous avons également plus de 100 colonnes qui sont superflues par rapport aux besoins, donc une certaine sélection de colonnes sera nécessaire.
Avant d’entrer dans le vif du sujet, nous souhaitons toutefois voir rapidement combien de niveaux de site il y a :
crawl_depth 0 1 1 70 10 5 11 1 12 1 13 2 14 1 2 303 3 378 4 347 5 253 6 194 7 96 8 33 9 19 Not Set 2351 dtype: int64
Donc, à partir de ce qui précède, nous pouvons voir qu’il y a 14 niveaux de site et que la plupart d’entre eux ne se trouvent pas dans l’architecture du site, mais dans le sitemap XML.
Vous pouvez remarquer que Pandas (le package Python pour la manipulation des données) ordonne les niveaux de site par chiffre.
C’est parce que les niveaux de site sont à ce stade des chaînes de caractères et non des chiffres. Ceci sera ajusté dans le code suivant, car cela affectera la visualisation des données (‘viz’).
Maintenant, nous allons filtrer les lignes et sélectionner les colonnes.
# Filter for redirected and live links
redir_live_urls = crawl_data[['url', 'crawl_depth', 'http_status_code', 'indexable_status', 'no_internal_links_to_url', 'host', 'title']]
redir_live_urls = redir_live_urls.loc[redir_live_urls.http_status_code.str.startswith(('2'), na=False)]
redir_live_urls['crawl_depth'] = redir_live_urls['crawl_depth'].astype('category')
redir_live_urls['crawl_depth'] = redir_live_urls['crawl_depth'].cat.reorder_categories(['0', '1', '2', '3', '4',
'5', '6', '7', '8', '9',
'10', '11', '12', '13', '14',
'Not Set',
])
redir_live_urls = redir_live_urls.loc[redir_live_urls.host == website]
del redir_live_urls['host']
print(redir_live_urls.shape)
Redir_live_urls
(4055, 6)
 Andreas Voniatis, novembre 2021
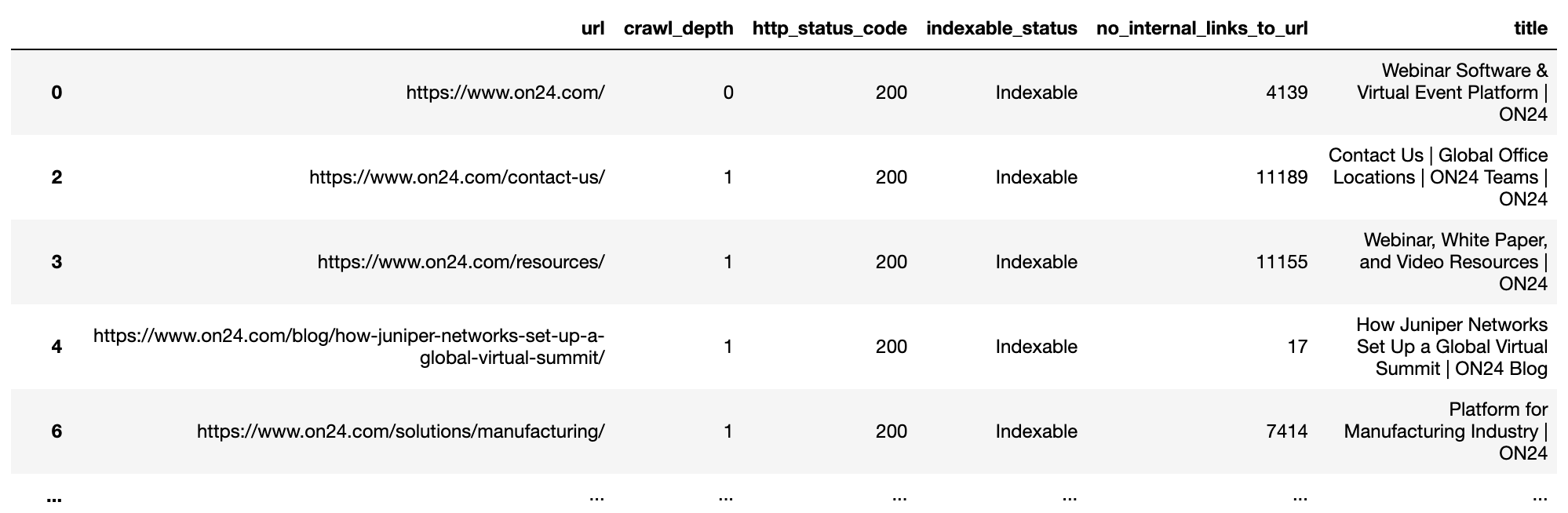
Andreas Voniatis, novembre 2021En filtrant les lignes pour les URL indexables et en sélectionnant les colonnes pertinentes, nous obtenons maintenant un cadre de données plus rationnel (pensez à la version Pandas d’un onglet de feuille de calcul).
Exploration de la distribution des liens internes
Nous sommes maintenant prêts à analyser les données et à avoir une idée de la façon dont les liens internes sont distribués globalement et par profondeur de site.
from plotnine import *
import matplotlib.pyplot as plt
pd.set_option('display.max_colwidth', None)
%matplotlib inline
# Distribution of internal links to URL by site level
ove_intlink_dist_plt = (ggplot(redir_live_urls, aes(x = 'no_internal_links_to_url')) +
geom_histogram(fill="blue", alpha = 0.6, bins = 7) +
labs(y = '# Internal Links to URL') +
theme_classic() +
theme(legend_position = 'none')
)
ove_intlink_dist_plt
 Andreas Voniatis, novembre 2021
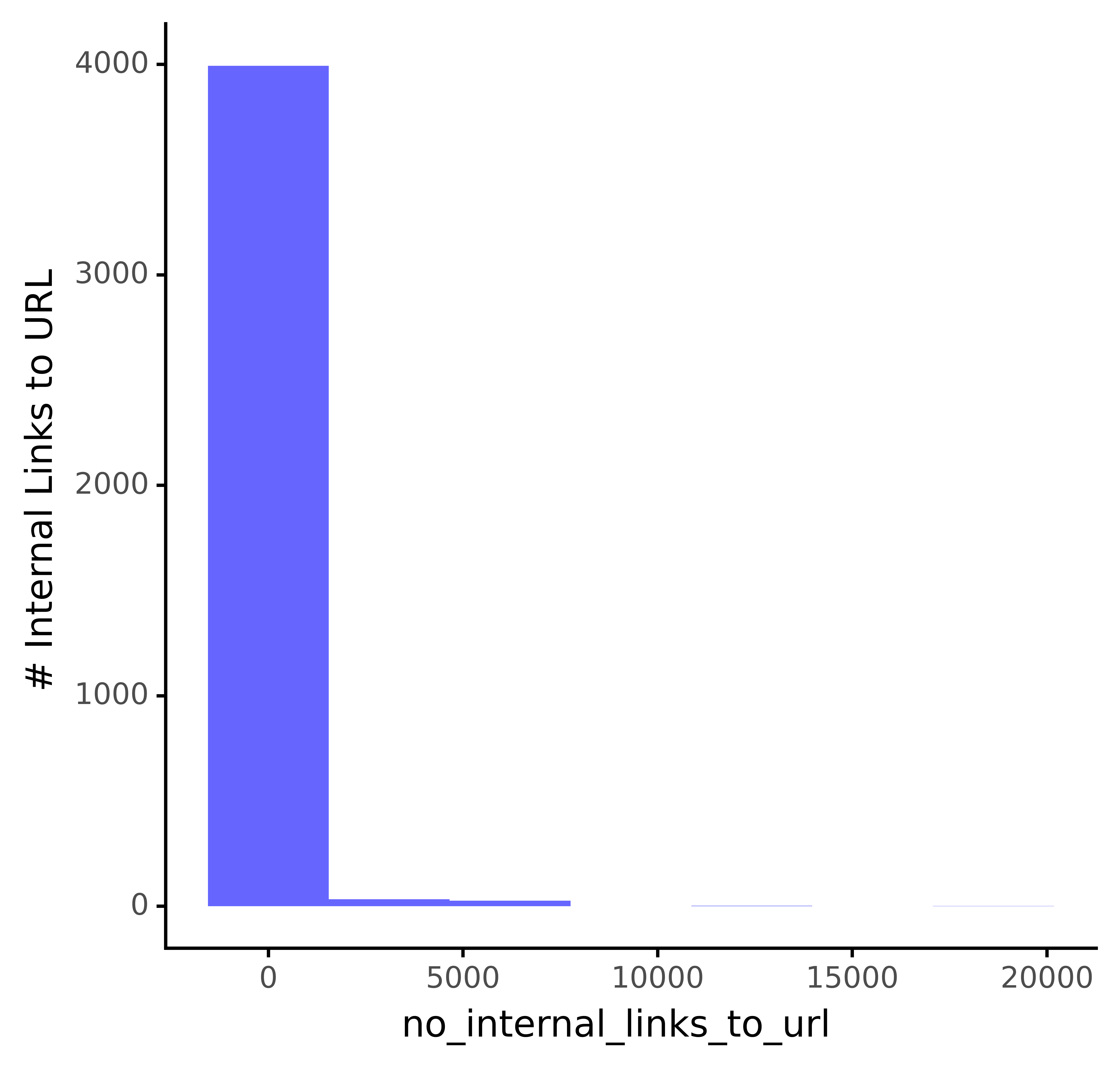
Andreas Voniatis, novembre 2021D’après ce qui précède, nous pouvons constater que la plupart des pages n’ont pas de liens. L’amélioration des liens internes serait donc une occasion importante d’améliorer le référencement.
Obtenons quelques statistiques au niveau du site.
crawl_depth 0 1 1 70 10 5 11 1 12 1 13 2 14 1 2 303 3 378 4 347 5 253 6 194 7 96 8 33 9 19 Not Set 2351 dtype: int64
Le tableau ci-dessus montre la distribution approximative des liens internes par niveau de site, y compris la moyenne (mean) et la médiane (quantile de 50%).
Ceci est accompagné de la variation au sein du niveau du site (std pour écart type), qui nous indique à quel point les pages sont proches de la moyenne au sein du niveau du site ; c’est-à-dire, à quel point la distribution des liens internes est cohérente avec la moyenne.
Nous pouvons déduire de ce qui précède que la moyenne par niveau de site, à l’exception de la page d’accueil (profondeur d’exploration 0) et des pages de premier niveau (profondeur d’exploration 1), varie de 0 à 4 par URL.
Pour une approche plus visuelle :
# Distribution of internal links to URL by site level intlink_dist_plt = (ggplot(redir_live_urls, aes(x = 'crawl_depth', y = 'no_internal_links_to_url')) + geom_boxplot(fill="blue", alpha = 0.8) + labs(y = '# Internal Links to URL', x = 'Site Level') + theme_classic() + theme(legend_position = 'none') ) intlink_dist_plt.save(filename="images/1_intlink_dist_plt.png", height=5, width=5, units="in", dpi=1000) intlink_dist_plt
 Andreas Voniatis, novembre 2021
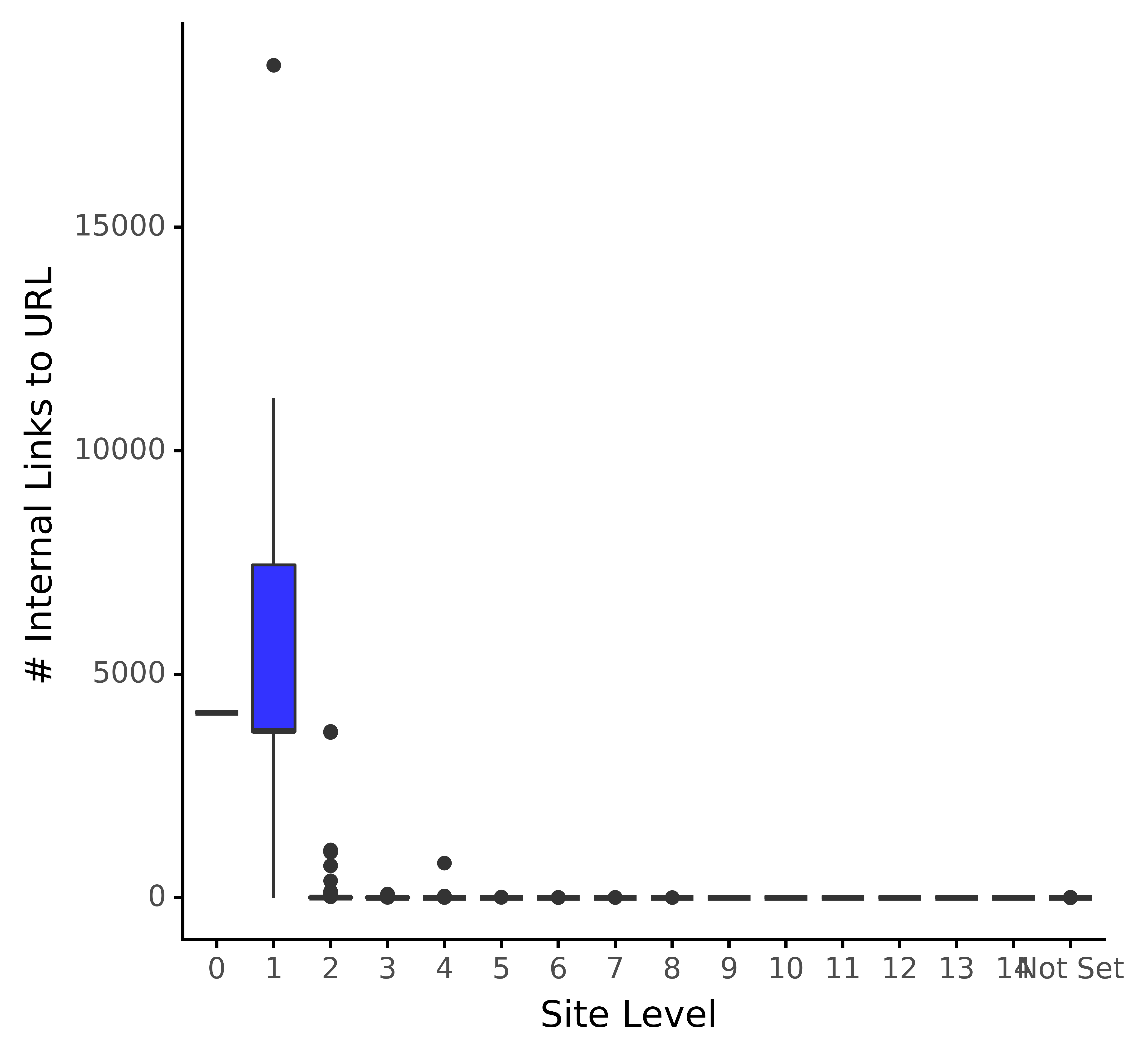
Andreas Voniatis, novembre 2021Le graphique ci-dessus confirme nos commentaires précédents selon lesquels la page d’accueil et les pages directement liées à celle-ci reçoivent la part du lion des liens.
Avec les échelles telles qu’elles sont, nous n’avons pas beaucoup de visibilité sur la distribution des niveaux inférieurs. Nous allons corriger cela en prenant un logarithme de l’axe des y :
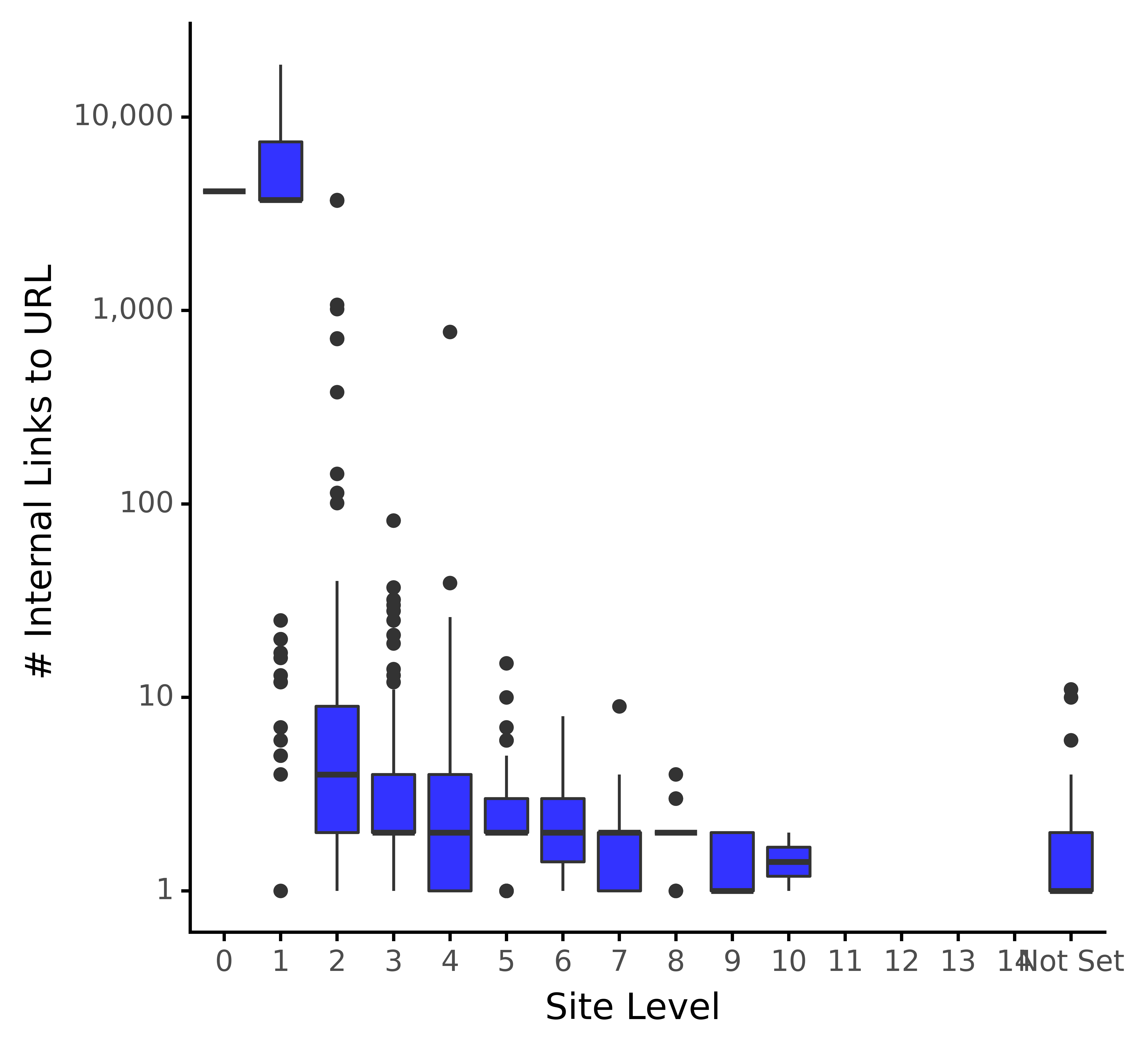
# Distribution of internal links to URL by site level from mizani.formatters import comma_format intlink_dist_plt = (ggplot(redir_live_urls, aes(x = 'crawl_depth', y = 'no_internal_links_to_url')) + geom_boxplot(fill="blue", alpha = 0.8) + labs(y = '# Internal Links to URL', x = 'Site Level') + scale_y_log10(labels = comma_format()) + theme_classic() + theme(legend_position = 'none') ) intlink_dist_plt.save(filename="images/1_log_intlink_dist_plt.png", height=5, width=5, units="in", dpi=1000) intlink_dist_plt
 Andreas Voniatis, novembre 2021
Andreas Voniatis, novembre 2021L’image ci-dessus montre la même distribution des liens avec la vue logarithmique, ce qui nous aide à confirmer les moyennes de distribution pour les niveaux inférieurs. C’est beaucoup plus facile à visualiser.
Étant donné la disparité entre les deux premiers niveaux de site et le reste du site, cela indique une distribution asymétrique.
Par conséquent, je vais prendre un logarithme des liens internes, ce qui aidera à normaliser la distribution.
Maintenant nous avons le nombre normalisé de liens, que nous allons visualiser :
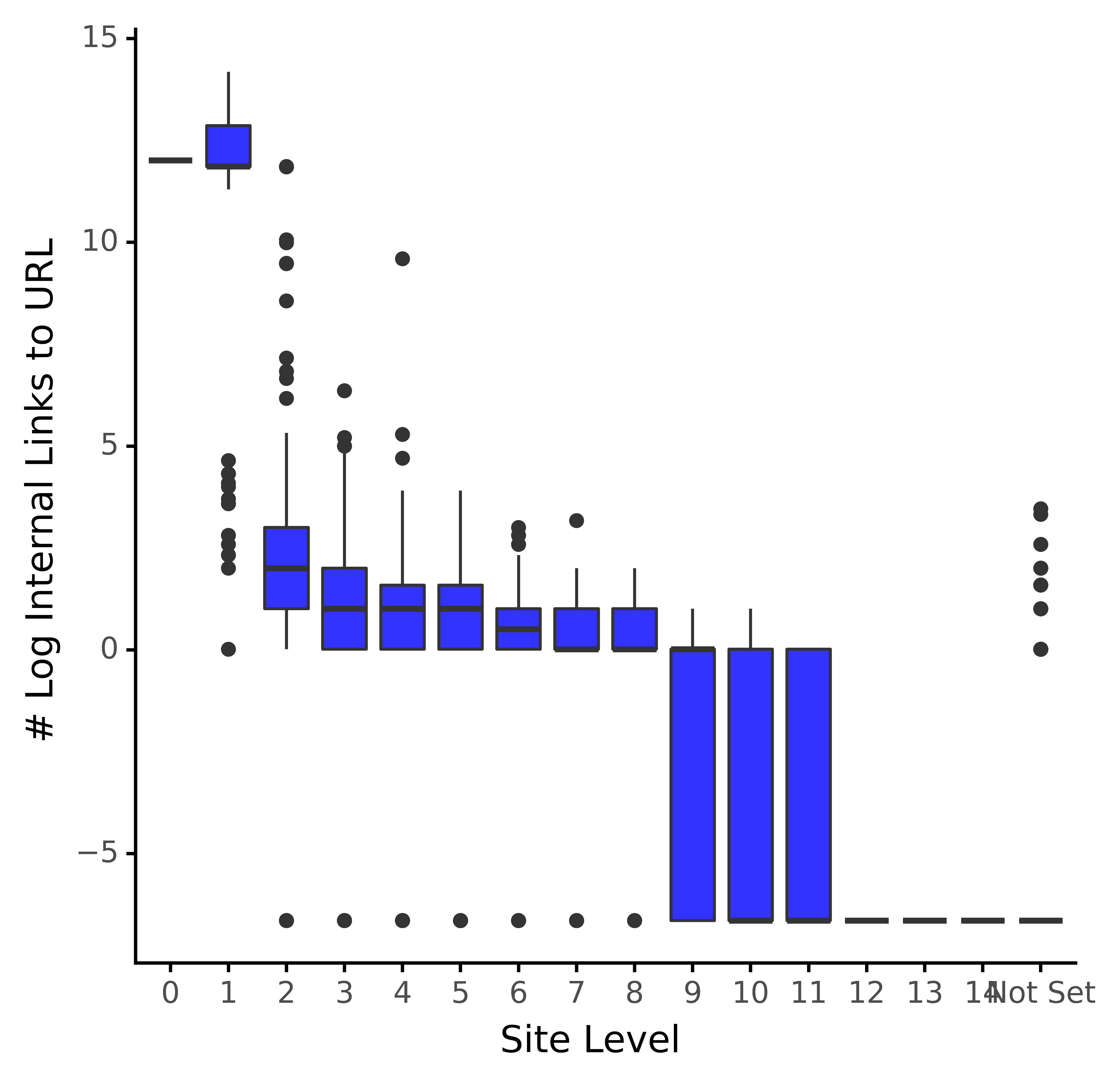
# Distribution of internal links to URL by site level intlink_dist_plt = (ggplot(redir_live_urls, aes(x = 'crawl_depth', y = 'log_intlinks')) + geom_boxplot(fill="blue", alpha = 0.8) + labs(y = '# Log Internal Links to URL', x = 'Site Level') + #scale_y_log10(labels = comma_format()) + theme_classic() + theme(legend_position = 'none') ) intlink_dist_plt
 Andreas Voniatis, novembre 2021
Andreas Voniatis, novembre 2021D’après ce qui précède, la distribution semble beaucoup moins asymétrique, car les boîtes (intervalles interquartiles) présentent un changement d’échelon plus progressif du niveau du site au niveau du site.
Cela nous permet d’analyser les données avant de diagnostiquer les URL sous-optimisées du point de vue des liens internes.
Quantifier les enjeux
Le code ci-dessous calculera le 35e quantile inférieur (terme de science des données pour percentile) pour chaque profondeur de site.
# internal links in under/over indexing at site level
# count of URLs under indexed for internal link counts
quantiled_intlinks = redir_live_urls.groupby('crawl_depth').agg({'log_intlinks':
[quantile_lower]}).reset_index()
quantiled_intlinks = quantiled_intlinks.rename(columns = {'crawl_depth_': 'crawl_depth',
'log_intlinks_quantile_lower': 'sd_intlink_lowqua'})
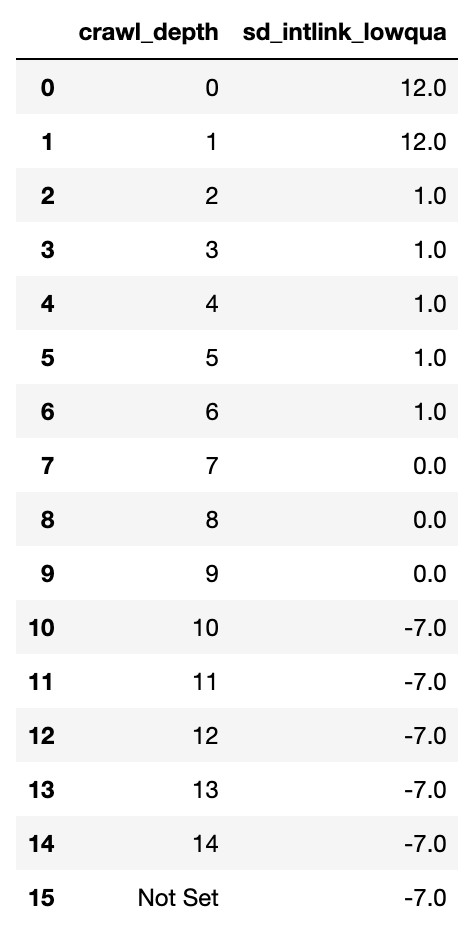
quantiled_intlinks
 Andreas Voniatis, novembre 2021
Andreas Voniatis, novembre 2021Le tableau ci-dessus montre les calculs. Les chiffres n’ont aucune signification pour un spécialiste du référencement à ce stade, car ils sont arbitraires et ont pour but de fournir un seuil pour les URL sous-liées à chaque niveau du site.
Maintenant que nous avons le tableau, nous allons le fusionner avec l’ensemble des données principales pour déterminer si l’URL, ligne par ligne, est sous-liée ou non.
# join quantiles to main df and then count redir_live_urls_underidx = redir_live_urls.merge(quantiled_intlinks, on = 'crawl_depth', how = 'left') redir_live_urls_underidx['sd_int_uidx'] = redir_live_urls_underidx.apply(sd_intlinkscount_underover, axis=1) redir_live_urls_underidx['sd_int_uidx'] = np.where(redir_live_urls_underidx['crawl_depth'] == 'Not Set', 1, redir_live_urls_underidx['sd_int_uidx']) redir_live_urls_underidx
Nous avons maintenant un cadre de données avec chaque URL marquée comme sous-liée sous la colonne »sd_int_uidx » comme 1.
Cela nous permet d’additionner la quantité de pages de sites sous-liées par profondeur de site :
# Summarise int_udx by site level
intlinks_agged = redir_live_urls_underidx.groupby('crawl_depth').agg({'sd_int_uidx': ['sum', 'count']}).reset_index()
intlinks_agged = intlinks_agged.rename(columns = {'crawl_depth_': 'crawl_depth'})
intlinks_agged['sd_uidx_prop'] = intlinks_agged.sd_int_uidx_sum / intlinks_agged.sd_int_uidx_count * 100
print(intlinks_agged)
crawl_depth sd_int_uidx_sum sd_int_uidx_count sd_uidx_prop 0 0 0 1 0.000000 1 1 41 70 58.571429 2 2 66 303 21.782178 3 3 110 378 29.100529 4 4 109 347 31.412104 5 5 68 253 26.877470 6 6 63 194 32.474227 7 7 9 96 9.375000 8 8 6 33 18.181818 9 9 6 19 31.578947 10 10 0 5 0.000000 11 11 0 1 0.000000 12 12 0 1 0.000000 13 13 0 2 0.000000 14 14 0 1 0.000000 15 Not Set 2351 2351 100.000000
Nous voyons maintenant que malgré le fait que la page 1 de la profondeur du site ait un nombre de liens par URL supérieur à la moyenne, il y a encore 41 pages qui sont sous-liées.
Pour être plus visuel :
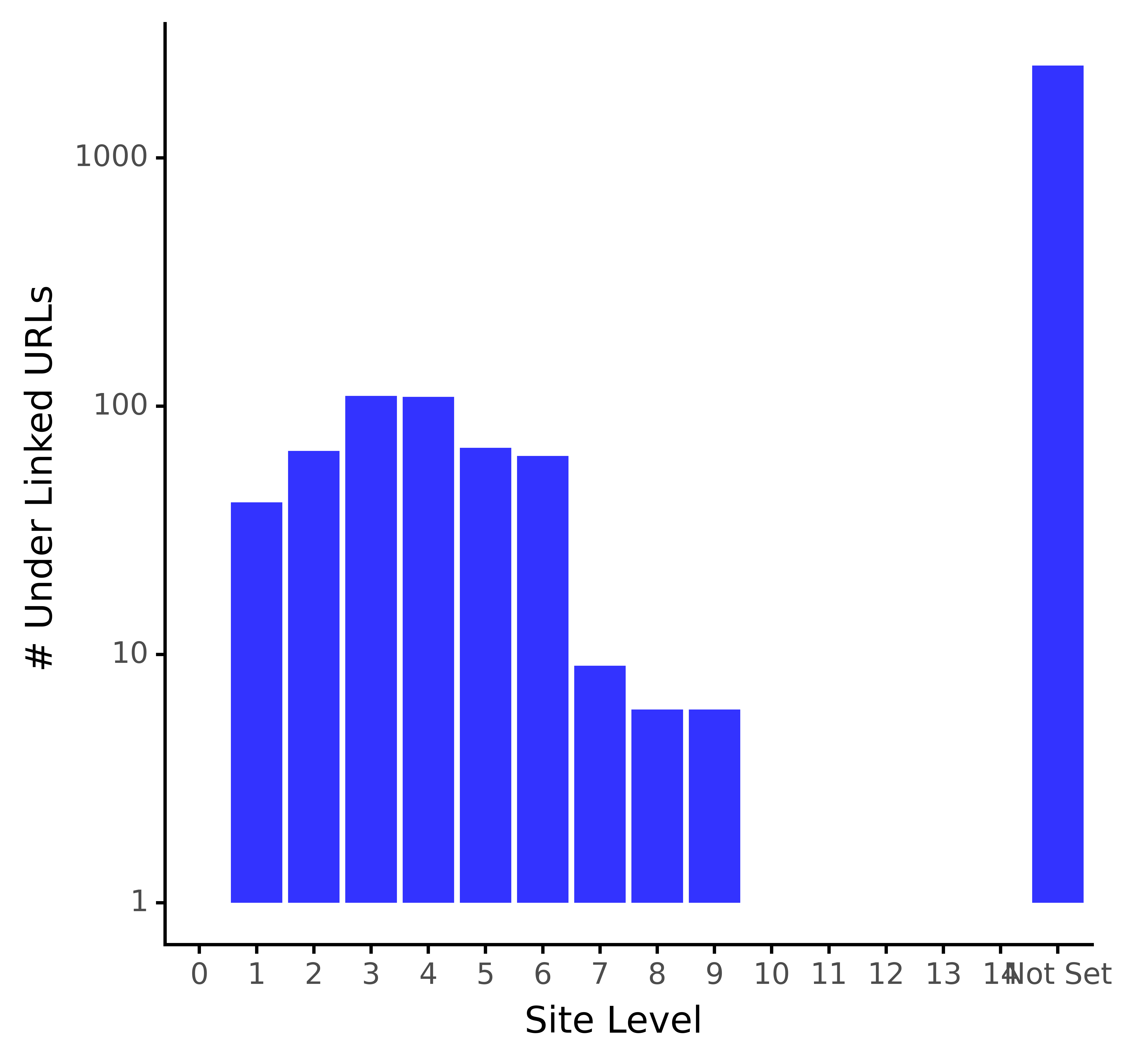
# plot the table depth_uidx_plt = (ggplot(intlinks_agged, aes(x = 'crawl_depth', y = 'sd_int_uidx_sum')) + geom_bar(stat="identity", fill="blue", alpha = 0.8) + labs(y = '# Under Linked URLs', x = 'Site Level') + scale_y_log10() + theme_classic() + theme(legend_position = 'none') ) depth_uidx_plt.save(filename="images/1_depth_uidx_plt.png", height=5, width=5, units="in", dpi=1000) depth_uidx_plt
 Andreas Voniatis, novembre 2021
Andreas Voniatis, novembre 2021À l’exception des URL XML sitemap, la distribution des URL sous-liées semble normale, comme l’indique la forme en cloche. La plupart des URL sous-liées se trouvent dans les niveaux de site 3 et 4.
Exportation de la liste des URL sous-liées
Maintenant que nous avons une idée des URL sous-liées par niveau de site, nous pouvons exporter les données et trouver des solutions créatives pour combler les lacunes dans la profondeur du site, comme indiqué ci-dessous.
# data dump of under performing backlinks
underlinked_urls = redir_live_urls_underidx.loc[redir_live_urls_underidx.sd_int_uidx == 1]
underlinked_urls = underlinked_urls.sort_values(['crawl_depth', 'no_internal_links_to_url'])
underlinked_urls.to_csv('exports/underlinked_urls.csv')
underlinked_urls
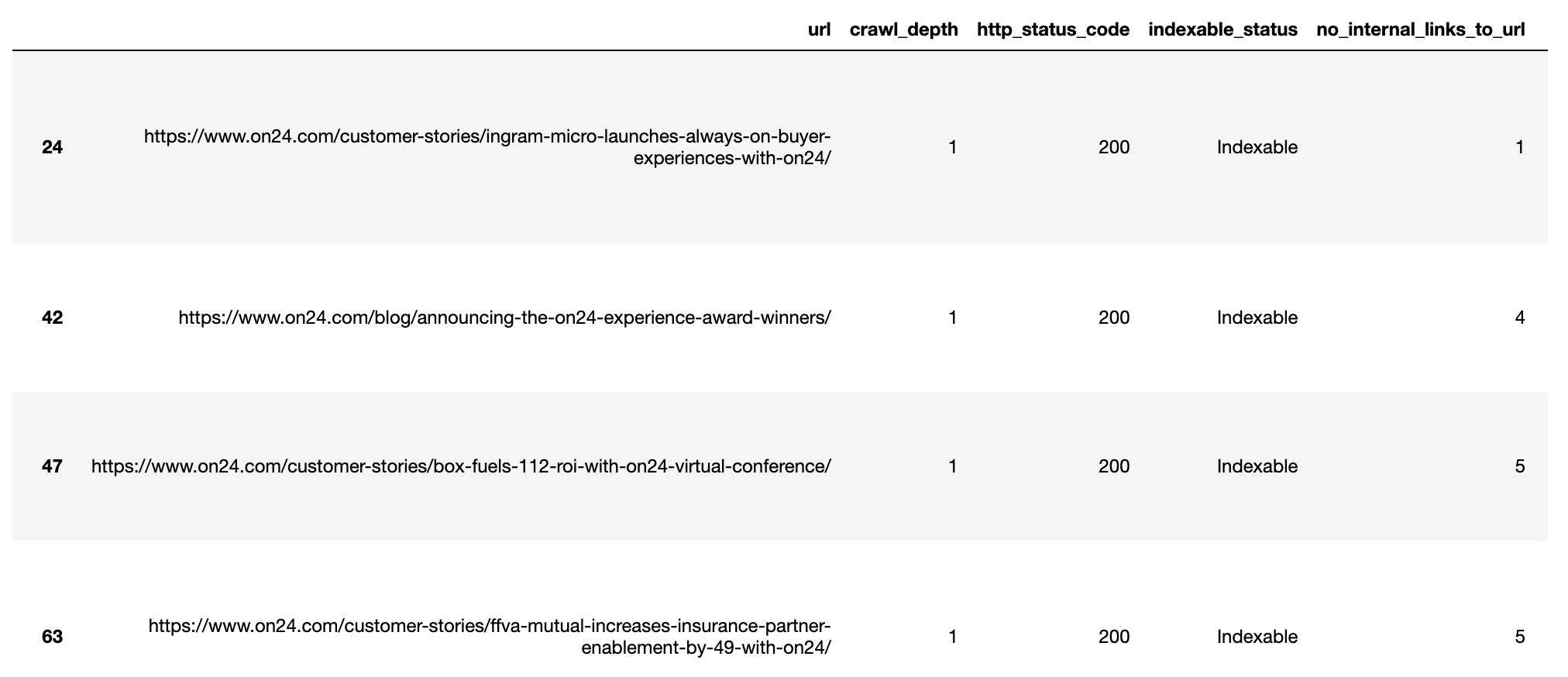 Andreas Voniatis, novembre 2021
Andreas Voniatis, novembre 2021Autres techniques de science des données pour la création de liens internes
Nous avons brièvement abordé la motivation de l’amélioration des liens internes d’un site avant d’explorer la manière dont les liens internes sont répartis sur le site par niveau de site.
Nous avons ensuite procédé à la quantification de l’étendue du problème de sous-liaison, à la fois numériquement et visuellement, avant d’exporter les résultats pour les recommandations.
Naturellement, le niveau du site n’est qu’un aspect des liens internes qui peut être exploré et analysé statistiquement.
D’autres aspects qui pourraient appliquer des techniques de science des données aux liens internes incluent et ne sont évidemment pas limités à :
- L’autorité de niveau de page hors site.
- Pertinence du texte d’ancrage.
- Intention de recherche.
- Parcours de recherche de l’utilisateur.
Quels sont les aspects que vous souhaiteriez voir couverts ?
Veuillez laisser un commentaire ci-dessous.
Plus de ressources :
Image en vedette : Shutterstock/Optimarc






{kind=link}